SnowETL
Maximize Your Business Potential with Strategic Data Utilization

SnowETL: Delivering Business Value
- Utilize All Available Data Across Your Company: Improve business processes and gain a competitive advantage by harnessing your company’s comprehensive data resources.
- Leverage the Latest, Most Up-to-Date Data: Drive superior business decisions and achieve better results using the most current data available.
- Low Entry Threshold: Easily create data pipelines by just saving a Python script.
- Access Archived Data Effortlessly: Enhance your strategic approaches with the capability for in-depth analysis of archived data.
- Focus on Data, Not Infrastructure: Invest your resources in analyzing data, rather than in developing complex and costly infrastructure.
Gather your data in existing infrastructure with reduced effort
- No Extra Infrastructure Needed: ETL occurs entirely within Snowflake
- No DevOps Involvement Required: There’s no need to involve DevOps to configure the data pipeline.
- Low Entry Threshold: Easily create data pipelines by just saving a Python script.
- Centralized Data Storage: Aggregate data from various sources into one centralized storage.
- Simple Architecture and Quick Setup: The system ensures easy implementation and quick deployment.
- Full Access to Python Libraries: Utilize any Python library without restrictions.
- Full Access to Source Code: Complete transparency with access to the source code.
Keep control over your data with reduced costs
- No Warehouse Costs During Data Ingestion: Avoid fees for running a warehouse while ingesting data.
- No Extra Tools Needed: Only a Snowflake user account is required.
- Low Data Storage Costs: All data is stored cost-effectively on Snowflake’s stage.
How Does It Work – User-independent
- Scheduled Execution: The Python script is executed at predefined time intervals.
- Output File Management: Files are saved to a dedicated directory or stage.
- Delta Detection: Capable of detecting differences between the current and previous files to process deltas.
- Cost-Efficient Data Loading: Data can be loaded into Snowflake tables using Serverless Tasks, eliminating compute costs without the need for a running warehouse.
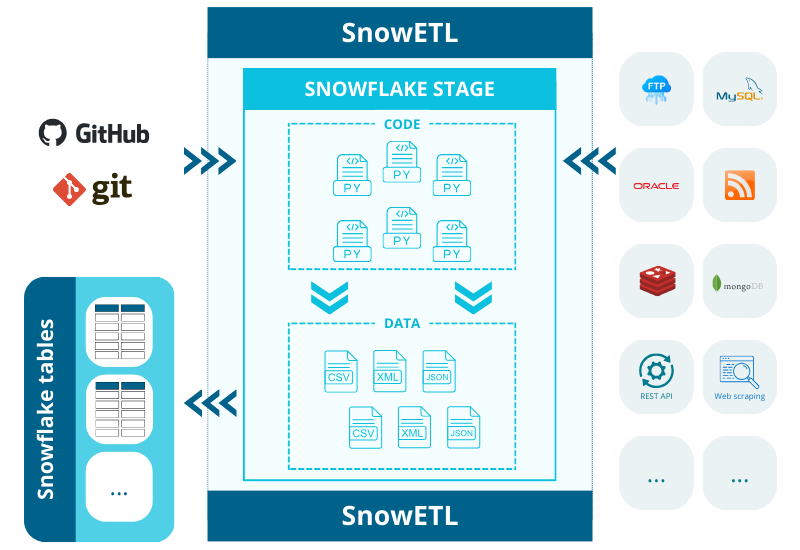
SnowETL – architecture
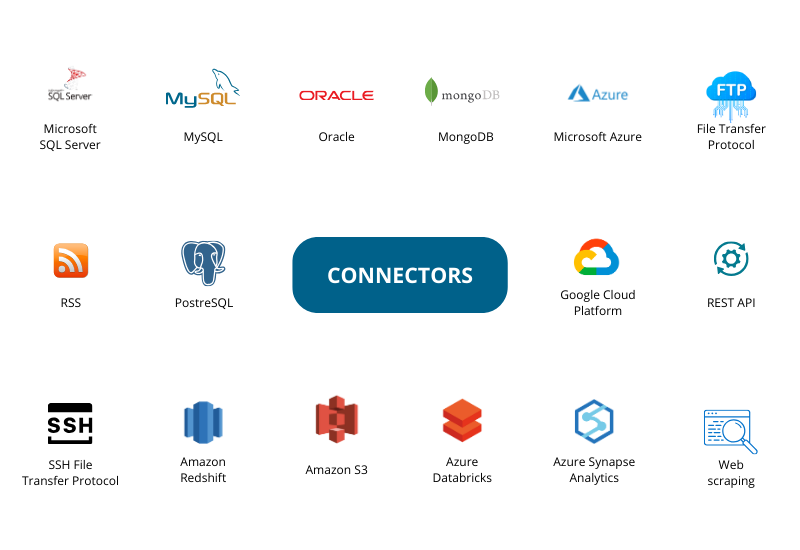
SnowETL – sample connectors
SnowETL currently supports a diverse range of connectors, and we are continuously enhancing its capabilities to support even more.
SnowETL – why?
Do you face the following issues when sharing data with business users?
- It takes too long.
- It requires the involvement of technical specialists.
- It costs too much.
- It requires additional infrastructure.
SnowETL solves these issues. It is:
- Faster – data pipelines are created faster.
- Easier – anyone with Python skills can create data pipelines.
- Cheaper – requires no additional components or extra effort.
- Simpler – requires no additional infrastructure.

CONTACT US
+48 22 398 47 81